In diesem Modul lernen die Studierenden den Data-Science-Prozess kennen: Sie lernen Daten zu verstehen, aufzubereiten, zu modellieren und zu evaluieren, um so datengetriebene Antworten auf praktische Fragen aus dem Marketing und dem Handel zu generieren.
Das Modul ist als Vorlesung mit integriertem Seminar gestaltet, in deren Rahmen die Studierenden die vermittelten Lehrinhalte direkt am PC nachvollziehen, die Übungen in Kleingruppen bearbeiten und vorstellen sowie am Ende der Veranstaltung ihre Bearbeitung einer Fallstudie aus dem Marketing bzw. dem Handel präsentieren.
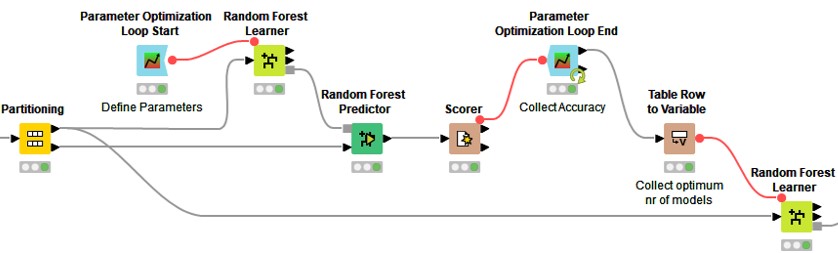
Das geschieht unter Zuhilfenahme der an der Universität Konstanz entwickelten Data-Mining-Software KNIME. Über das "visuelle Programmieren" in Workflows kann KNIME im gesamten Data-Science-Prozess eingesetzt werden und enthält zahlreiche Module („Knoten“) für die Analyse von Big Data (u.a. Apache Hadoop inkl. Hive und Spark), Text Mining, Machine Learning (u.a. Decision Trees, Random Forests), Neuronale Netze und Deep Learning (Keras-Layer).
- Lehrende(r): Christian Knobloch
- Lehrende(r): Ulrich Hendrik Schröder